We have been exploring improved
interactions with video by
combining real time, client-side automatic content analysis with direct manipulation. We are
extending this work in the mixmeet system.
A current focus is building real-time search functionality in synchronous web meetings.
Relevant publications include
[DocEng 2015].
multimedia search & interaction
A long term research goal is to build interactive systems that enable users to work with visual data
with the facility and familiarity with which they use text documents.
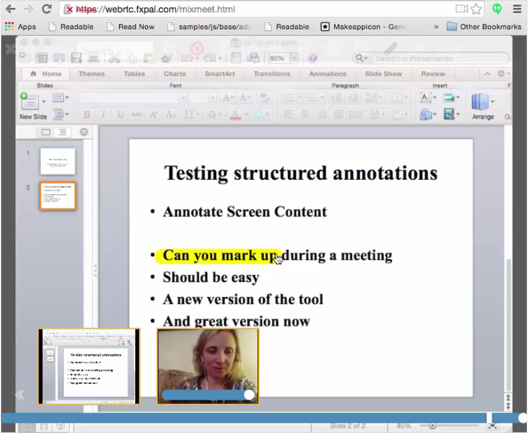 |
enhancing web-based video conferencing:
|
 |
enhancing interaction with expository video:
We have explored improving
interactions with video with a concentration on the growing genre of "how-to" content. A consistent focus is allowing
users to navigate and reuse content by combining real time, client-side automatic content analysis with direct manipulation.
|
|
enhancing search for web-distributed presentation video:
TalkMiner was a public web site that aggregates lecture webcasts distributed on the internet (e.g. from YouTube). The site allows users to both search for videos from various sources at once, and also to search within those videos for specific segments of interest. Automatic analysis identifies frames in which slides appear, and extracts their text. The text indexes the slides, allowing text search across and within videos. When a relevant video is browsed, the specific slides and corresponding video segments in which they appear can be directly accessed. Details appear in [MM 2010]. |
|
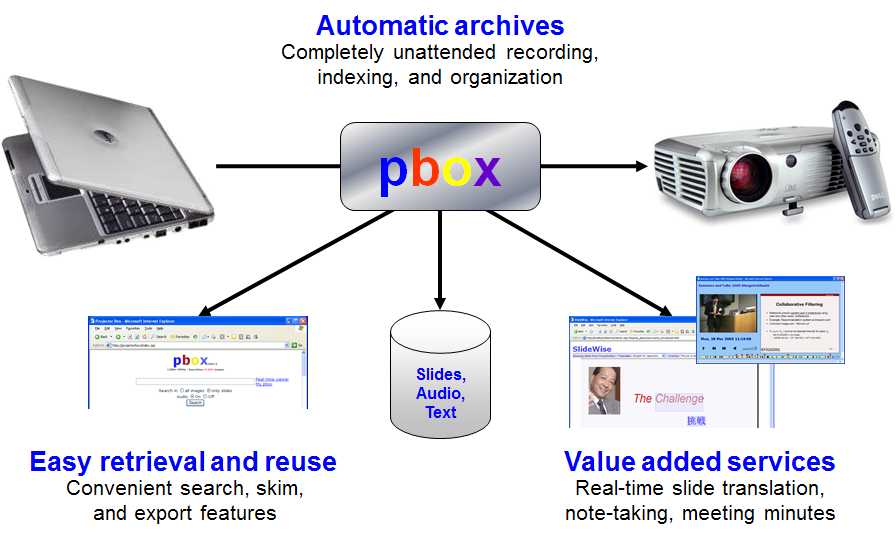 |
projector-based lecture capture and management:
ProjectorBox (PBox) is a lightweight system for capturing lecture content using the projector feed and a microphone. The projector RGB input is split and analyzed to detect slide frames and slide changes, while also capturing the room audio via the mic. The resulting unique slide frames are indexed using optical character recognition enabling text based search through the accumulated presentation content. Relevant publications include [SPIE, 2005] and [ELEARN, 2005]. |
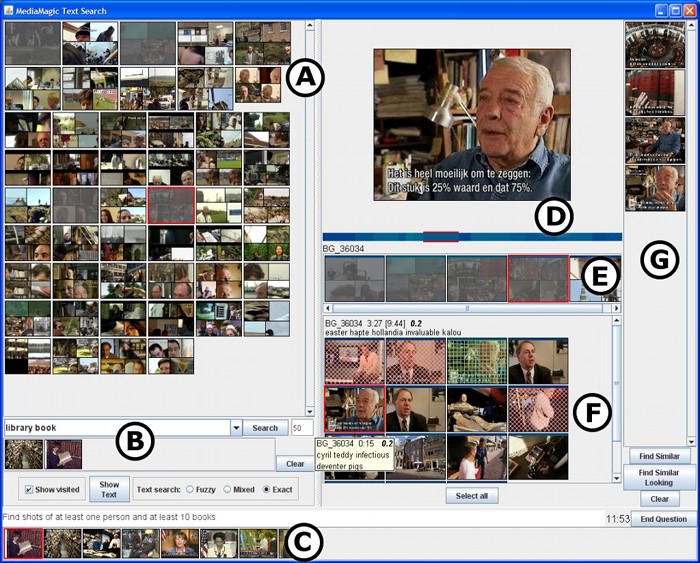 |
interactive video search:
For the interactive search task of TRECVID, we designed a system combining multi-level segmentation with powerful interface elements and validated the system successfully. We automatically group video shots according to a text-based topic segmentation. These "stories" are the central organizational unit by which the interface presents video shots to users in reponse to their queries. More details may be found in [CIVR, 2005] and [Girgensohn, et al., 2006]. In 2007 and 2008, we explored collaborative (multi-user) variations of our system. We also validated a text-free version of the interface that also performed competitvely by combining automatic shot categorization and similarity within the existing user interface [CIVR 2008]. |